|
Current Events | Write to us | TELRI Main Page | TELRI Seminar |
Developing a Russian-Finnish Parallel Text Corpus for Lexicographic Work and Translation Studies: Towards Automation of Routine Procedures
Mikhail Mikhailov, Hannu Tommola
Kortelahdenkatu 19 D 77
33210 Tampere
Finland
e-mail: lomimi@uta.fi
Nowadays more and more linguistic research is based on text corpora. Obviously, the main users of text corpora are lexicographers although text corpora are quite helpful in language teaching, translation studies and various directions of applied linguistics in general. For compiling dictionaries the reasearchers need a lot of empirical data to build word lists and collect examples. The data collected from a large corpus is more reliable than what can be obtained from other dictionaries. Even if dictionaries are used as a basis for new dictionaries it will be safer to consult a text corpus as well. With help of a corpus previously unregistered meanings can be identified, examples of usage can be found, etc.
Nowadays text corpora are quite widely used for compiling monolingual dictionaries. Nevertheless it is still a problem to use text corpora in bilingual lexicography. Of course it is possible to use two text corpora but it would be more useful to have parallel texts and tools for looking up words and their translations as well as parallel contexts.
The aim of the research project running at the Department of Translation Studies of University of Tampere is to compile a Russian-Finnish corpus of parallel texts. The corpus will consist of Russian fiction texts and their translations into Finnish. The corpus is not very big but it will be equipped with efficient search tools for analysis of parallel texts.
At present we have a substantial corpus of Russian prose (4.5 m. running words) and have started to collect the translations into Finnish and to modify the software for running the parallel text corpus.
We have provided the above mentioned corpus of Russian prose texts with certain tools for building word lists and concordances. The texts are stored as ANSI text files. Each text is registered in the Microsoft Access database and supplied with a description. The database is used for data processing as well. The user can build concordances for specified word(s) or word combination(s). He/she can also use the word list for query-making. It is quite easy to specify context size (in sentences) and comparison mode for the main and the second key (whole word / start of word / end of word / any part of word) as well as the second key position (same sentence / next word).
However, the most difficult part of the project will be automated parallel concordancing. The program should find the keywords in the text A which will be achieved by excluding particles, conjunctions, prepositions, etc., as well as words with a very broad meaning (e.g. "idti"). Then the program finds possible translation equivalents for the keywords in the language B and searches for the portion of the text B where most of the keywords in question can be found. If our hypothesis is true, the program will be able to find parallel places if a) the context is long enough; b) enough keywords were found; c) the translation is close enough to the original.
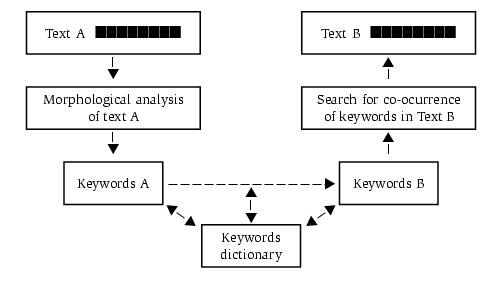
Figure 1. Search for parallel contexts
The parallel text corpus will be useful in the fields of comparative studies, translation studies, and bilingual lexicography. It will make it possible to find how a word is actually translated, which is sometimes quite different from what is expected according to dictionaries. It will also be quite possible to monitor usage of certain grammatical forms or constructions and ways of translating them into another language.
Back to Newsletter no. 9.