NEWSLETTER
No. 4
Issue
No. 1 | Issue
No. 2 | Issue
No. 3 | Issue
No. 5
Wolfgang Teubert, Coordinator of TELRI
Norbert Volz, Project Manager
1. Our Present Position
The TELRI Plenary Meeting held in Mannheim, June 14-18, 1996, marked not only the middle of the project's timetable but also the turning point from TELRI as a network under construction to a functional and highly successful pan-European language resources infrastructure. Our external reviewers gave us a favourable evaluation of the performance and motivation displayed by all partners -- an achievement we can duly be proud of, but also an obligation to maintain this positive image for the future.
The encouragement received from our external evaluators has shown us that it is now time to forge the link between research and infrastructure activities as agreed upon at the previous Steering Committee Meeting.
2. Change of WG Structures
Facing these new challenges, we have decided to restructure the scope, membership, and coordination of TELRI working groups, especially in the network and service area, and to change the ratio between infrastructure-oriented and research-oriented Working Groups.
As a first step towards this aim, WG "Seminars" was changed to WG "Morphosyntactic Annotation", and WG "User Needs" was transformed into WG "Validation". Also, a survey was held among all TELRI partners in order to collect and identify further needs for changes in Working Group scopes and structures and to subsequently set up a new Working Plan for the next period of the project.
The Joint Meeting of the WGs Joint Research, Lingware Availability, and Networking at the Mannheim Plenary Meeting and the Nancy Workshop on Service Tools, August 28 - September 1, have also shown that there is a strong demand for closer cooperation and joint activities between the members of these Working Groups that could be beneficia to the project as a whole. Further joint activities will include a Workshop on Public Domain Software Tools as well as continuing and expanding the work on the Plato Parallel Corpora and Birmingham's COBUILD Bridge Dictionary project.
3. Accomodation of Workplan Items
For the end of 1996, TELRI plans to prepare a proposal for a new COPERNICUS project "Multilingual Terminological Database" along with international partners such as ISO, Infoterm, or ELRA. This will serve as a repository for the terminology of Language Engineering and Language Technology worldwide.
Further activities in the area of documentation of LR/LT activities and resources include a bibliography on corpus linguistics, to be completed by the IDS early next year, and the establishment of a searchable database for TELRI resources on the WWW, where a prototype version has already been installed and can be accessed via the TELRI Website.
Working Group "Joint Research" (Coordinator: John Sinclair, Birmingham) is continuing its work on the localisation of the COBUILD Student Dictionary to the various TELRI languages. In an electronic form, these dictionaries can easily be linked and, thus, serve as a multilingual lexicon.
The newly constituted Working Group "Validation" (Coordinator: Primoz Jakopin, Ljubljana) will, in cooperation with the ELRA Written Language Resources Validation Panel, establish an analytical framework for the validation of non-SGML corpora and tools.
TELRI will prepare a proposal for a workshop on Morphosyntactic Annotation, to be held in Spring 1997. Participants will have the opportunity to discuss annotation standards and recommendations with experts from EAGLES, MULTEXT, PAROLE, and other related projects in order to adapt existing guidelines for morphosyntactic annotation to suit the peculiarities of the non-EU-languages represented in TELRI as a further step towards the development of comparable pan-European language resources.
For June 1997, TELRI plans a workshop on Translation Equivalents, to be organised jointly by WG Joint Research and the Tuscan Word Centre. For this activity, links will also be established with the PAROLE Association Working Group "Multilingual Lexicon".
Also for 1997, TELRI is going to launch the proposal for a new project "PAROLE East" to be submitted under the next COPERNICUS call for proposals. Complementary to the existing LE-PAROLE project, PAROLE East aims to create standardised language resources (comparable corpora and lexicons) in those CEE and NIS countries that already have some resources available for conversion according to existing PAROLE standards.
4. The Future of TELRI
In their evaluation report, our external reviewers, Prof. Alexander Barulin (Moscow) and Dr. Mark Liberman (Philadelphia) strongly supported TELRI's intention to set up an independent legal body, "TELRI Association", in order to enable the continuation of our activities once the present funding period has expired. We are now in the process of establishing the TELRI Association as a registered association under German civil law, which we hope will be finished by the end of this year.
In response to another desideratum expressed in the Evaluation Report, TELRI will continue to expand and improve its presence on the World Wide Web. As a first step, we have established a dedicated position of TELRI WWW Officer and have contracted this job to a graduate student who will maintain and update our WWW pages. In addition to the already existing English WWW pages, it is planned to set up individual pages for each of the TELRI languages as well as to install "interactive" WWW pages for quick and easy information on TELRI resources and services. We thus hope to make TELRI not only a viable and successful institution but also a long-term "brand name" on the corpus linguistics information market.
(continued)
Note of the Editors:
We bring two more contributions to the discussion on tagging started in the preceding issue of TELRI Newsletter. Since we believe that corpus annotation belongs to the hot problems in the present state of development of corpus linguistics, we would welcome any reports on on-going projects, proposals of innovative approaches or comments on the already published contributions.
the LE-PAROLE Tagset Specifications
Norbert Volz, IDS Mannheim
1. Introduction
According to Leech and Wilson (1994, p.3), "Corpus annotation is the practice of adding interpretative, especially linguistic, information to a text corpus, by coding added to the electronic interpretation of the text itself."
Thus, morphosyntactic annotation, also known as part-of-speech (POS) tagging, is the annotation of the grammatical class of each text token. POS tagging is primarily carried out automatically by using rule-based or stochastic (e.g., Hidden Markov Models) tagging algorithms (see e. g. Hladká and Hajiè, 1995). Therefore, we will concentrate on machine tagging of corpus texts, either fully automatic or semi-automatic, i.e., involving human intervention at some stages.
Within large multilingual projects such as PAROLE or TELRI, most of the available corpus tools such as taggers, access, maintenance and storage software, etc. are developed at different locations and are often also based on different existing resources and programs; therefore, common encoding standards and guidelines have to be developed in order to port the various tools and resources to other partner sites in the project.
2. "Task-oriented" and "Resources-oriented" Approach
When it comes to the actual design of a tagset, two basic approaches can be distinguished with regard to the scope of the envisaged application. To make this distinction more clear, I will describe these two different modi operandi as either "task-oriented" or "resources-oriented".
2.1 "Task-oriented" or "economical" approach
A task-oriented approach aims to produce the maximum level of morphosyntactic annotation in the most economical way with those resources and tools that are readily available at present. It is mainly used if the tagged texts will serve as input to some concrete application such as context analysis or translation software, where the amount of morphosyntactic information available is enough to fulfill the requirements of the superordinate task. In other words, morphosyntactic features that cannot be identified by the tagger will not be included into the tagset; also, the number of ambiguities left to be resolved will be reduced as the tagset inventory is more or less restricted to those features known to be available and unambiguous. The advantage of those "stripped" or "poor" tagsets ("poor" meaning only having a small number of tags 100) lies in their rather high tagging success rates of around 96% (Erjavec 1996). This advantage, however, is paid for with a certain indistinctness and lack of flexibility of the tagset.
2.2 "Resources-oriented" approach
A resources-oriented approach aims mainly at the creation of large generic corpora. These annotated corpora not only serve as state-of-the-art material for today's applications, but, in the form of "reference corpora", serve also as a textual basis for future research. Therefore, it is desirable to reach a maximum level of morphosyntactic annotation, i.e., as detailed and fine-grained as the lexical encoding. Of course, this "ideal" level cannot yet be achieved with the automatic tagging algorithms available at present and, therefore, still requires a fair amount of manual intervention (tagging, checking, disambiguation) if carried out to its full extent. The aim is not only to accomodate the annotation level feasible at present but also to allow for further refinements and the inclusion of additional features. This requirements call for an "open" or "fringed" tagset structure, resulting in large, "rich" tagsets with sometimes more than 1800 possible combinations of obligatory tags (Ridings 1996).
3. Multilingual Tagset Design: The PAROLE Approach
3.1 "Common core" tagset
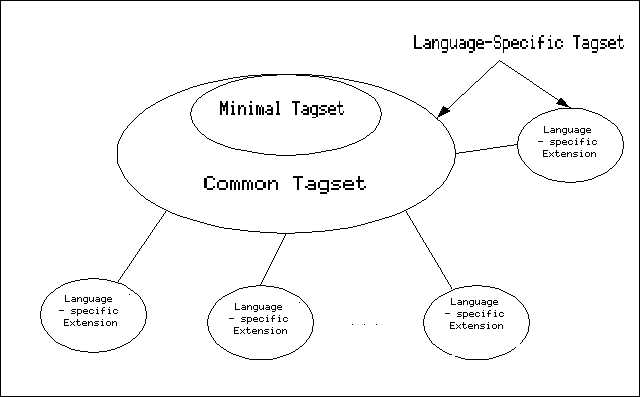
The notion of a "common core" tagset is based on the EAGLES three-level distinction of obligatory, recommended, and optional features. The obligatory "minimal tagset" encompasses all morphosyntactic features considered as common to all involved languages. The "common tagset" includes additional features pertinent to most languages, and whose annotation is recommended (but not mandatory) for various reasons. The third, "optional" level is realised by language-specific extensions in order to cover the singular features of each language. Common core or "skeleton" tagsets are mainly applied by projects like MECOLB that use a task-oriented approach according to the definition given above. (Cloeren 1995, p. 3)
Figure 1, taken from Volz and Lenz (1996, p.1) shows the typical design of a common core tagset.
Fig. 1. "Common Core" tagset design
However, the fixed character of a common tagset following the above principle will imply large language-specific extensions to make full use of the available tagging algorithms, especially for the languages outside of the EC language group for which these EAGLES recommendations were designed in the first place.
3.2 The PAROLE approach
The PAROLE tagset specifications are also based on the EAGLES recommendations formulated by both the Corpus and Lexicon Working Groups. The main idea was to provide a resources-oriented, multilingual tagset allowing for a high granularity of annotation.
It became clear, however, that designing a generic and portable, yet very fine-grained tagset across a variety of languages is not a feasible task, because both language-dependent and theory-dependent decisions have to be taken when mapping lexicon mark-up inventories to common corpus tagsets.
The main focus of specification standards within PAROLE has, therefore, been on the notation and overall tagset design rather than on linguistic criteria for the annotation itself. The idea is that a well documented and feasibly designed tagset will enable an adequate exploitation of the corpus under "real-world" conditions, that is, with imperfect data and with some theoretical aspects still unsolved, but able to accomodate future refinements and extensions. The resulting tagset specifications are thus based on the present state of the art, but not restricted to it.
PAROLE has therefore applied a "mosaic" approach where the distinction between "generic" and "language-specific" features is apparent within the tag proper rather than being an inherent feature of a particular "sub-class" of the tagset.
Basically, three steps were necessary to design the common tagset specifications:
- Collection and comparison of the categories and features required by all PAROLE languages.
- Establishing a general notation convention that allows for a gradual distinction between common and language-specific features.
- Definition of the hierarchy between features.
3.2.1 Collection and comparison of the categories
The selection of categories and features follows the EAGLES-based PAROLE specifications for the lexicon as described in the Appendix 1 of the LE-PAROLE contract: Lexicon Architecture and Model and the specifications given in the MLAP-PAROLE report "Task 4.2.2: Lexicon: Morphosyntactic Specifications: Language Specific Instantiations", Pisa 1996.
3.2.2 General notation convention
A predefined number of attribute positions 1 to x is kept for all languages. The number of positions refers to the common features shared by at least two languages in PAROLE. Language-specific or optional features that do not correspond to these positions can be included in the tag by using positions x+1 to n.
Example: General notation convention for nouns:
| Common |
Optional/Language-specific |
|||||||
| Position |
1 |
2 |
3 |
4 |
5 |
6 |
... |
n |
| Features |
PoS |
Type |
Gender |
Number |
Case |
e.g.,
Contrast |
||
| Attributes |
Noun |
common
proper |
masc.
fem. neuter |
singular
plural |
Nom.
Gen. Dat. Acc. |
marked
unmarked |
The German noun "(des) Hundes" ("the dog's/of the dog") would be tagged as follows:
| PoS: |
Noun |
N |
Ncmsg |
| Type: |
common |
c |
|
| Gender: |
masculine |
m |
|
| Number: |
singular |
s |
|
| Case: |
Genitive |
g |
The equality symbol "=" is used for an attribute that is not tagged within a certain language tagset although present within the lexicon. The hyphen symbol "-" is used for features that are not applicable for a specific combination of attributes and values, e.g., if the attribute does not apply to a particular category subclass whilst still applying to the category as such. The hyphen is also used for features not applicable to a particular lexical item although pertinent to the rest of its paradigm. Generally speaking, the equality sign denotes "external", mainly tagging, restrictions; the hyphen denotes "internal" restrictions imposed by the lexicon.
The vertical bar "|" denotes tagging ambiguities; the "+" character denotes intrinsic ambiguities (similar to the "external" and "internal" restrictions described above). Both characters follow the entire coding sequence and seperate the two or more tagging alternatives.
Example: Dutch "jolijt" would be annotated as Ncms--+Ncns--
NB: The actual characters to be used for tagging restrictions and tag separation were still under discussion at the time of completion of this article. The above description follows the current state of specifications (March 1996) and may be altered in the course of the LE-PAROLE project.
4. References
Cloeren (1995): J.Cloeren (ed.): MLAP 93-21 MECOLB: WP5 - Quality Assessment. Tasks 5.2-5.5. Deliverables D11-D14. Final Report. Nijmegen: TOSCA Research Group
Erjavec (1996): T.Erjavec: TELRI WG 5 Report: Corpus Tool Identification (forthcoming)
Hladká and Hajiè (1995): B. Hladká and J. Hajiè: TELRI, Proceedings of the First European Seminar: A Simple Czech and English Probabilistic Tagger: A Comparison. Tihany, Hungary.
Calzolari (1996): N.Calzolari et al. (ed.): MLAP 63-386 PAROLE: WP 4.2.2: Lexicon: Morphosyntactic Specifications: Language Specific Instantiations. Pisa: ILC
Leech and Wilson (1994): G.Leech and A.Wilson: "Morphosyntactic Annotation". EAGLES Document EAG-CSG/IR-T3.1 (Version of October 1994). Pisa: EAGLES Consortium
Ridings (1996): D.Ridings: PAROLE Text Representation. Electronic document on the Göteborg University WWW server. (http://svenska.gu.se/~ridings/textrep/) Göteborg: Språkdata
Volz and Lenz (1996): N.Volz and S.Lenz: MLAP 63-386 PAROLE: WP 4.1.4a: Multilingual Corpus Tagset Specifications (Version of March 1996). Mannheim: IDS
Prof. PhDr. Frantisek Cermák, DrSc.
The Institute of the Czech National Corpus
Faculty of Philosophy, Charles University
nám. J. Palacha 2, Prague 1, 110 00
The Czech Republic
e-mail: Frantisek.Cermak@ff.cuni.cz
The Czech National Corpus (CNC) which is being built up by a concerted effort of a number of academic institutions (mostly universities) is conceived of as a general and possibly representative research source of the contemporary, primarily written Czech Language of the size of some 100 million words in its first stage (while provisions are made for its further growth). Its three other branches include a sample historical corpus, a half-million corpus of authentic spoken language and a general archive serving as a first repository of texts which have been acquired. Out of the many envisageable and possible targets of the CNC the primary one is to serve as a basis for a new dictionary of the Czech language.
At present, some 50 million of textual words might be available in the archive from where, after a clean-up, conversion and TEI/SGML text tagging they gradually flow into the CNC itself. The written part of the Czech National Corpus contains some 30 million words now and the remaining first-stage representative figure of 100 million words might be available in some two years' time. Since the whole project is supported by some government grants where one of the stipulations was to make a substantial part of it publicly accessible, in the spring of this year (1996) first modest version of CNC has gone public. Thus, some 20 millions of newspaper and journal language are to be found now at the following Web WWW pages http://ucnk.ff.cuni.cz/english with some brief instruction how to search it. Since the respective software management tools are still under development, the access ways are somewhat limited so far, primarily to a concordance form.
The policy pursued so far has been to include whole texts (except advertisements, especially those in English or German, and texts written in Slovak which have been removed); yet this whole-text approach might be questioned later on, as the figures keep growing and some attention might be paid to sampling here, too.
Although a number of minor research problems still have to be solved as far as the envisaged rough picture of the CNC's representative parts is concerned, it was decided to use, as a general background (to be modified), the results of a sociological research undertaken a short time ago. It has been decided to choose, as the sole and primary criterion to be explored in the enquette, that of language reception, i.e. quantitative proportions of various types of language that its users are exposed to, whether actively or in a passiveway. The major results can be summarized in the following (numbers are given in %, the spoken language is not included):
READING --specialized/technical 33,5
--nonspecialized 66,5
-journals 56
-fiction cum poetry etc 10
-other 0,5
Just as a marginal information only, let me say that the percentage of the spoken and written language was found to be in the proportion of 67 : 33.
While the proportions of various technical fields can be estimated on the basis of, for example, the circulation, edition and readership of technical journals, primarily, a serious consideration is required in the neglected field of the size of representation of these fields in newspapers and journals of general nature, too. Another related persistent problem not to be found solved anywhere is the double-face quality of many nouns which are both technical terms and general usage words at the same time (bread, pencil etc. are, next to being general, definitely terms, too, at least for their manufacturers) which makes this technical-nontechnical boundary and proportion still more difficult.
Of course, some correction of these figures will be attempted later on, too, stressing other points next to this one, i.e. the language reception.
Reported by: Mariana Damov, Tomaz Erjavec, Alexander Geyken, Ann Lawson.
Mariana Damov
e-mail: mariana@ims.uni-stuttgart.de
My project in the LORIA computer pool was to make a prototype for an interractive query system of the TELRI resources using text encoding tools and the DILIB workbench. For this purpose I encoded the list of available in electronically readable form list of TELRI resources into TEI-lite. Following the structure of the document, which was something like a bibliography of data and tools registered by TELRI members, I marked the single items as lists (of resources and tools) and put them together into divisions with the names of institutions as heads. Then I used the DILIB system to recode the file from TEI into SGML, and to index the institution names word by word. As DILIB is a tool compatible with the Web, I designed the query interface for the TELRI resources in HTML format with links to the prepared DILIB routines, so that the queries could be posted and the results shown directly on a Web browser. The described efforts produced a small prototype application of a Web page providing the ability to consult the TELRI resources in an interactive way. The Web site for this prototype is for the time being the TELRI home page in Nancy (http://www.loria.fr/~romary/TELRI/essai.html). It is also currently linked to the TELRI home page in Mannheim (/telri/whats-new.html) under the item "what's new". I am grateful to Emanuel, Florence and Valeria who spent time to share their experience with me, and assisted me to accomplish my project sucessfully.
Tomaz Erjavec
e-mail: Tomaz.Erjavec@ijs.si
The main practical task I came to Nancy with was to test-align the English and Slovene version of the novel "1984" by George Orwell, using the XCorpus software. This text is being SGML encoded in the scope of the Copernicus MULTEXT-East project (see http://nl.ijs.si/ME/Corpus/1984/).
In Nancy we managed to sentence segment and align a part of this text, and a demo is available at the Nancy TELRI Web page. However, some problems remain, mostly caused by the heavy markup already present in the current version of "1984", which sometimes confuses the segmenter and aligner. A new version of XCorpus is to be released shortly and will be installed at the Ljubljana site. With this release, we will re-do the alignment and expect better results.
Having watched Ann working with the English text of Plato, I became intrigued and attempted to SGML encode its Slovene translation, which had been produced by ZRC SAZU in Ljubljana. Although I made a good start in Nancy, it took me another two days when I came home to finish this work. In the hope that others (especially members of TELRI WG9) will find the description of this process useful, I made the WWW page http://nl.ijs.si/telri-wg5/Republic/, which describes the up-translation of the Slovene component of the "Republic" corpus.
Alexander Geyken
e-mail; alex@cis.uni-muenchen.de
Apart from the courses we followed in Nancy, I spent the majority of my time in Nancy working on a short extract of a bilingual readings in German and French. My declared goal was not to encode a whole book, but to experience if it is possible in only ONE afternoon via the XCorpus toolbox to encode ASCII text into a SGML/TEI conformant structure, to process sentence alignment on this structure and to display these results on the web. And all this was possible! Of course, the XCorpus tools cannot do any miracles but they are of great help with TEI headers, the hierarchical structure of SGML elements, the correct (re-)numbering of attribute id's and idrefs, and last but not least with sentence alignment.
Ann Lawson
e-mail: ann@clg.bham.ac.uk
I spent the majority of the time in Nancy working on the English editions of Plato's "Republic". Having taken both the older (Jowett) and the newer (Harvard) translations to Nancy, I soon realised that the new version was in a very poor state for automatic work. I then concentrated mainly on the old version. I worked on TEI encoding, divison marking, paragraph marking and sentence segmentation. I disentangled various problem cases such as hyphenated words and some quotes, but was unfortunately unable to get a good enough version of the text to align it with another while in Nancy. Hopefully that will soon follow!
RESEARCHES IN CENTRAL ASIA
Hamdam ARZIKULOV,
Laboratory for Language Engineering, Samarkand State Institute of Foreign Languages
e-mail: hamdam@samarkand.silk.glas.apc.org
The international Speech Statistics Groups held a two-day meeting, on May 20-21, 1996, at the Samarkand State Institute of Foreign Languages - main linguistic university in the new sovereign states of Central Asia where European and Oriental languages are studied . The purpose of the meeting was to explore ways in which research into Turkic language engineering can be integrated to produce a multilingual and polifunctional system so-called Turkic linguistic automaton (TURKLINGTON). The choice of the Samarkand linguistic university is quite understandable: it is known that Samarkand has always been a generally recognized cradle of the Central Asia Moslem culture. Besides the Republic of Uzbekistan is a new Central Asiatic state with the most stable geopolitic and economic situation.
On the other hand the independence status of the new Turkic republics necessitates to create their own information industry. Therefore language engineering (LE) turns with interest to Kazakh, Kyrgyz, Uzbek, Azerbaijan and other Turkic languages. In Kazakhstan the research body headed by Prof. K.Bektayev is creating a machine fund (i. e. thesaurus) of the Kazakh language, working on English-Kazakh MT and statistical-informational typology of Turkic texts. The Uzbekistan LE research group headed by Prof. H. Arzikulov consists of three teams (Samarkand, Tashkent and Nukus collectives). The group is engaged in creating a machine thesaurus of Uzbek and Karakalpak languages, in designing English-Uzbek and Uzbek-English MT systems and computer-aided language learning (CALL) of the Uzbek, English and French languages. In addition, the Samarkand research team works out MT patterns for Arab and Persian languages. In Bishkek (capital of Kirgizistan) Prof. T. Sadykov and his colleagues from the Kyrgyz Academy of Sciences are developing methods of automatic Turkic text synthesis. Ph.D. M.Aiymbetov from the Karakalpak Pedagogical Institute studies statistical proprieties of Turkic texts. The models of formal morphological analysis of Turkic word-forms are worked out by Prof. M. Mahmudov's LE group in the Azerbaijan Academy of Sciences in Baku.
The meeting at the Samarkand State Institute of Foreign Languages was attended by 52 people from Turkic and Russian academic, university and industrial sities. It was opened by Prof. Yusuf Abdullaev, the rector of Samarkand State Institute of Foreign Languages (SSI of FL), followed by an introduction to the synergetic problems of NLP by acad. R.Piotrowski (Hertzen Univ of Russia). The second talk was given by Prof. T. Sadykov (Kyrgyz Academy of Sciences) who described the state of the art in automatic analysis of Turkic word-forms and its morphological aspects.
Prof. H.Arzikulov (SSI of FL) pointed out that commercially viable NLP - systems depend crucially on getting access to real text patterns. Therefore automatic dictionaries and machine grammars are developed in the TURKLINGTON not on the well known dichotomy "Language - speech" but on the basis of the trichotomy "Language system - speech system - text". It is important to emphasize that NLP leaned upon the language system produces a primitive lexico-grammatical translation, where as a linguistic automaton working with speech pattern it would provide a more adequate MT, text abstracting or spell-checking. Asst.Prof. M. Aiymbetov (Nukus Univ) presented a new taxonomy classification of Turkic languages and dialects on the basis of their lexico-statistical properties.
After thePlenary Session three Section sessions were organised. The first session, "Computer-Aided Text Processing", began with the talks of Asst.Prof. D.Urinbaeva (Samarkand Univ) entitled "Automatic Analysis of Amir Timur's Works" and that of Prof. B. Urinbaev (SSI of FL) "Lexico-Grammatical Features of Amir Timur's Works". The third talk "Computer-Aided modeling of mathematical terminology of the Tamerlan's epoch" was given by Asst. Prof. I.Hojiev (SSI of FL). Then Prof. B.Tursunov and M.Begmatov (SSI of FL) tried to convince the audience about the importance of for mal specification of textual unities for automatic pattern recognition. A survey of Turkic text automatic analysis was presented by Asst.Prof. Garipov (Bashkyriya Univ) and Prof.R.Kilichev (SSI of FL).
The second session considered "Computer-Aided West and Oriental Language Learning" and was opened by S. Doniyarova (SSI of FL), who talked about "Semantic Field in Lexics and its Computer Application in Language Learning". The second talk - "Teaching Computer-Aided Grammar" - was given by U. Umirzakov (Samarkand Univ). M.Choriyev (Karshi University), M. Boliev (Samarkand Med.School) and I.Akramova were the main participants in this discussion.
The third session of the meeting focused on the topic of "Computer Programs for NLP". This session was opened by Asst.Prof. A.Karshiyev, who gave a very interesting talk on Machine Translation from English into Uzbek. The talk "Design and implementation of a spell Check for Uzbek Language" was presented by E.Gujov (Samarkand Univ). This was followed by a series of short presentations on Automatic Analysis and Synthesis of Natural Language (U.Urinbaev, Samarkand Univ; O.Kholmurodov, Ssi of FL; S.Kobylov, Samarkand Univ; M.Ayimbetov, Nukus Univ).
Geert-Jan M. Kruijff , chairman of ESSLLI'96
e-mail: gj@ufal.mff.cuni.cz
After summerschools in Groningen (1989), Saarbrcken (1990), Leuven (1991), Colchester (1992), Lisbon (1993), Copenhagen (1994), and Barcelona (1995), this year's summerschool was held in Prague, Czech Republic, from August 12 until August 23, 1996. Alike the other summerschools, the main focus was the interface between logic, linguistics, and computation, particularly where it concerns the modelling of human linguistic and cognitive abilities. As such, the programme included courses, workshops and symposia covering a variety of topics within six areas of interest: Logic, Language, Computation, Logic and Computation, Computation and Language, and Language and Logic. Examples were Ivan Sag's symposium on "Syntax and Semantics of Coordination" (Language), Patrick Cousot's introductory course on "Abstract Interpretation" (Computation), John Carroll's workshop on "Robust Parsing" (Language & Computation), and Johan van Benthem's advanced course "Dynamic Logic and Information Flow".
Besides the approximately 55 courses, given by -in total- 70 lecturers from all over the world, there were also three invited evening lectures. This year's lectures were given by Barbara Partee ("Quantificational Domains, Focus, and Recursive Contexts"), Petr Sgall ("Prague School through the Epochs"), and Johan van Benthem ("The Common Concerns of Logic and Philosophy of Science").
ESSLLI'96 was attended by more than 440 people (including lecturers), among them being 40 grantees (in part funded by the Volkswagen Stiftung and the International Institute of the University of Tbingen/EACL). Except for Antarctica, all the world's continents were represented - making ESSLLI into more than just a (major) European experience!
Next year, ESSLLI will be held in Aix-en-Provence, France. For more information on ESSLLI'97, please go to their website at http://www.lpl.univ-aix.fr-/~esslli97
or send an email to esslli97@lpl.univ-aix.fr
ESSLLI'96 was organized under auspices of FoLLI (the European Association for Logic, Language and Information), Charles University, and the Czech National Technical University (ÈVUT).
Prague, February 10-21 1997
Organized by the Institute of Formal and Applied Linguistics,
Charles University, Prague
Hotel Krystal, Prague 6, José Martí Street
Emmon Bach (Univ. of Massachussetts, Amherst, USA):
Varieties of polysynthesis
Elisabeth Engdahl (Gteborg, Sweden):
Recent developments in theoretical syntax
Fred Jelinek (Johns Hopkins University, baltimore, USA):
Stochastic methods in linguistics
Ferenc Kiefer (Budapest, Hungary):
The morphology syntax interface
Bente Maegaard (Copenhagen, Denmark):
Evaluation of natural language processing products
Peter W. Nesselroth (Canada):
What is the deconstruction and why are they saying such terrible things about it
Ellen Prince (Univ. of Pensylvania, Philadelphia, USA):
Syntax-discourse interface
Helmut Schnelle (Univ. of Bochum, Germany):
The structure of language and the topography of language areas in the brain
John Sinclair (Birmingham, Great Britain):
Computerized lexica
Oliviero Stock (Trento, Italy):
Chart parsing and bidirectionality
Eloise Jelinek (USA):
Some specific phenomena of non-Indoeuropean langauges
The following Czech professors
have also been invited to give a talk:
Jan Hajiè: Computerized corpus of Czech language
Eva Hajièová: Recent research in topic-focus articulation
Oldøich Le[sinvcircumflex]ka: Czech structural linguistics
Jarmila Panevová: Dependency syntax
Jaroslav Peregrin: Some issues of theoretical semantics
Petr Sgall: Typology
The number of participants is limited. There are grants available for students from the post-communist countries covering the tution fee (including accommodation); applications for grants must be submitted before October 31st, 1996, with a recommendation of the student's supervisor (professor or senior researcher). The tution fee (including accommodation in double rooms with private showers and with buffet breakfast for 13 nights, lunches for 10 weekdays, a welcome party and all teaching materials) is 380 USD.
Further information: {brdickov, hajicova}@ufal.ms.mff.cuni.cz
ANDERSEN Poul
e-mail: m764@eurokom.ie
BECI Bahri
NEW!!!
e-mail: beci@igjl.tirana.al
BENKO Vladimírr
e-mail: jazybenk@savba.savba.sk
BIEN Janusz S.
e-mail: jsbien@plearn.edu.pl
Èermák Franti[sinvcircumflex]ek
e-mail: frantisek.cermak@ff.cuni.cz
ERJAVEC Toma
e-mail: et@cogsci.ed.ac.uk
FISIAK Jacek
Email: fisiak.plpuam11.bitnet
GELLERSTAM Martin
e-mail: gellerstam@svenska.gu.se
HAJIÈOVÁ Eva
HLADKÁ Barbora
e-mail: hajicova@ufal.mff.cuni.cz
hladka@ufal.mff.cuni.cz
JAKOPIN Primoz
e-mail: primoz.jakopin@uni-lj.si
JARO[Sinvcircumflex]OVÁ Alexandra
e-mail: sasaj@juls.savba.sk
NEW!!!
LAURENT Romary
e-mail: Laurent.Romary@loria.fr
KRUYT Truus
e-mail: kruyt@rulxho.leidenuniv.nl
MARCINKEVIÈIENÉ Rúta
e-mail: ruta.marcinkeviciene@vdu.lt
OIM Haldur
e-mail: hoim@psych.ut.ee
PAJZS Júlia
e-mail: pajzs@nytud.hu
PASKALEVA Elena
e-mail: hellen@bgearn.bitnet
PENCHEV Iordan
e-mail: jpen@bgearn.bitnet
SINCLAIR John M.
e-mail: j.sinclair@bham.ac.uk
SPEKTORS Andrejs
e-mail: aspekt@mii.lu.lv
TEUBERT Wolfgang
VOLZ Norbert
e-mail: telri@ids-mannheim.de
TUFIS Dan
e-mail: tufis@roearn.ici.ro
ZAMPOLLI Antonio
e-mail: paula@icnucevm.cnuce.cnr.it
*You can see detailed addresses in Newsletter No. 2.
Top of this issue |
TELRI Main Page |
{kind=link}