
NEWSLETTER
No. 5
Issue No. 1 | Issue No. 2 | Issue No. 3 |Issue No. 4
Ljubljana Workshop
| News form TELRI Working Groups
| On the lexicons
| Interesting Events
| List of Participants
Ann Lawson, University of Birmingham
The Working Group "Joint Research" is amongst the most fruitful research projects within the framework of the TELRI project, offering partners spanning most of Europe the opportunity to work together on a close and practical level. This group set out to collect, encode and distribute electronic text versions of a sample text, Plato's "Republic", with the aims of testing corpus alignment software and investigating new methods of extracting data about translation equivalents, collocations and phraseological units in various languages.
This newsletter provides a sample of the work currently ongoing in the encoding and alignment of parallel language texts, and the research subsequently carried out. The papers were presented at a weekend workshop on the 1st and 2nd February 1997 in Ljubljana, at the Jozef Stefan Institute, Slovenia, in which many members of Working Group "Joint Research" participated. The workshop was well timed, as most partners present had not only made an electronic version of Plato's "Republic" available, often encoded with additional information, but had also undertaken some preliminary work on parallel texts. The weekend offered a wonderful opportunity to discover first-hand the tasks other partners are tackling, the problems and issues they are encountering and perhaps most importantly of all, the solutions found to deal with them successfully.
In all, around 20 TELRI partners participated in the workshop, with local students and visitors swelling the number. Tomaz Erjavec organised the practicalities of weekend admirably, including computer access, accommodation and entertainment.
The weekend was split into four distinct sections according to the tasks involved and the papers being presented.
The first session dealt with the encoding of electronic texts in Standard Generalised Markup Language (SGML), sentence segmentation and structural markup in general. An afternoon was then spent looking in detail at the issue of alignment, in order to analyse parallel texts. The ideal, theoretical and practical considerations were explored with the benefit of first-hand experience and computer demonstrations.
The third session looked at partners' experiences and results of comparative analyses of translations, and their bearing on future research. The issue of translation equivalents in the texts as compared to traditional bilingual dictionaries was of special interest to many partners.
The final afternoon was spent discussing plans for the future. The Workshop and this publication have fuelled the motivation and enthusiasm of the partners to continue this line of work. All left the workshop with ideas and plans for both the near future in terms of further segmentation, alignment and analysis of texts, and for the longer-term future.
The Third TELRI Seminar, planned for late October 1997 at the Tuscan Word Centre, will discuss in more detail the issue of "Translation Equivalence". It will be an opportunity for TELRI to present further research findings to a wider audience of industry representatives. The Ljubljana workshop proved to be a vital intermediate stage towards such future ambitions.
More info on the Workshop is at http://nl.ijs.si/telri-wg5/LjWS.html.
Editorial | News form TELRI Working Groups | On the lexicons
| Interesting Events
| List of Participants
e-mail: Frantisek.Cermak@ff.cuni.cz
A Sample Analysis of Ways of Expressing AGREEMENT and DISAGREEMENT in the Translation of Plato's Republic into Czech and English.
O. Plato's Translated Texts in Czech and English.
The paper Czech version (Ústava) used has been that of the second Czech edition published by Svoboda/Libertas in Prague in 1993 and it is based on the Greek original as published in Paris 1932 by E. Chambry (Platon, Oevres Completes, tome VI, La république I-III. The first Czech translation is that of R. Hosek (the first translation being from J. Novotn[yacute], published in 1921, both published in Prague).
The paper English text used has been that of D. Lee, published in Penguin Books in its 2nd revised edition in 1974.
To get an electronic version, the Czech text had to be scanned, revised and corrected in various laborious ways and stripped of any additional text added by the editors.
1. Handling of both Texts.
At the time of the analysis there has been, unfortunately, neither a suitable aligner nor the English tagged text which I planned to use in a comparative study of Czech and English translation of Plato's Republic. The Czech version exists now in two forms: as a plain text and in the SGML format. My aim has been to analyse, at this stage, a sample of both texts as to the variability of corresponding expressions of agreement and disagreement. The Czech text, which has been tagged by the side numbers-cum-letters (a-b-c-d-e) but which could not use these markings as there has not been a corresponding English text at the time, however, has been hampered in its analysis in that it has then had to be analysed manually, together with the English one. This was due to a suitable aligner being unavailable. I have to say that the analysis and its preparation took, unfortunately, much more time than planned as both texts differ considerably in their treatment and distribution of text paragraphs which simply cannot be relied on. This must be somewhat of a disappointment for the alignment philosophy which so heavily relies just on paragraph alignment primarily.
2. An Analysis.
The random choice of the sample to be analysed fell on Chapter 2 (The Individual, The State, and Education). In the subsequent step, next to checking the overall distribution of both positive and negative expression of the attitude (2.1), I decided to take up, in some detail, the negative attitude, i.e. disagreement (2.2).
2.1 Overall Distribution of both Agreement and Disagreement:
CZECH: Agreement 102x :
-direct (yes/yes (ano) + qualifier): 24
-indirect (other than "yes", much longer and diverse): 78
Disagreement 23x :
-direct (no/no (ne) + qualifier): 22
-indirect (other than "no/not"): 1
Disagreement not expressed negatively (as against
English) or found missing 5
ENGLISH: Agreement 110x :
-direct (yes/yes + qualifier): 18
-indirect (other than "yes", much longer and diverse): 92
Disagreement 20x :
-direct (single no/not/im- or with qualifier): 20
-indirect (other than "no/not"): 0
Disagreement not expressed negatively (as against
Czech) or found missing 8
No attempt has been made, at this stage, to go into what is termed here "qualifier", but some illustration of what is meant can be seen from the examples below.
Some Conclusions:
A-Agreement : Disagreement in both languages approximately = 5 : 1
B-Agreement in both languages: 4 times more indirect than direct, while
C-Disagreement has a reverse situation: 19 times higher preference for a direct disagreement than for an indirect one. Moreover: diasagreement seems to rely, more than agreement, on various verb forms.
2.2 Distribution and Analysis of Disagreement Forms:
Only very general formal features have been picked up and scrutinized, such as presence or absence of morphological negation and cases of no correspondence. Numbers are auxiliary page numbers of the printouts used for the analysis.
ENGLISH: CZECH:
Nonsense! Nepovídej!
There can be no other Nevidím
No doubt x xOvsem
Impossible-repeated To opravdu moné není
Not at all Nikoliv
xI dare say x Já to nejsem schopen rozpoznat
No Ne
xQuite true x Vùbec ne
No doubt x xI já si to myslím
xCertainly x Jak by ne?
xWe must x To opravdu ne
Certainly not Nezdá se
xMost assuredly x Nemùe to b[yacute]t jinak
Certainly not To tedy ne
We cannot Ne, to v ádném pøípadì nedovolíme
- x Pøi Diovi, ne!
No, indeed Vùbec ne
Certainly not Ani to ne
No -
Impossible x xJak by bylo?
I cannot answer you To teï ovsem nemohu takto tvrdit
He cannot Jak by ne?
Impossible To je nemoné
Heaven forbid Ovsem, to ne
I cannot say To nevím
There is nothing more hateful x Ovsem, velmi
to them
That is inconceivable Ani zdaleka
None whatever Neexistuje!
2.3 A Commentary
It is certainly alck of basic, i. e. "negative", correspondence here which is most surprising. It boils down to two cases:
1-The translator has opted for the opposite polarity of expression (8 times in English and 5 times in Czech) which amounts to some astonishing 20 or more percent. One can only wonder what the Greek original has in these cases. Or
2-There is simply no corresponding form used at all, either positive or negative in one of the languages involved (one case in each language).
An interesting matter for conversation analysis and that of politeness is the obvious preference here, contrary to positive, i. e. agreement expressions, to shy at simple negative one-word expression. Also ways how these negative expressions are expanded is of much interest. To be able to arrive at any typicality here and what is less typical, one would need a much larger text, of course, and this is what the subsequent stage of the comparative analysis should be concerned with.
3. Conclusion and a Suggestion
I think that an analysis like this, if expanded, might lead to a number of insights and could fit in into a broader mosaic of both text analysis and search of translation equivalents, even though the latter is somewhat difficult once the original language is not used.
However, it is the basis of a reliable alignment which has to be found, which, as my experience shows, is not to be sought in paragraphs but in the broader a-b-c-d-e notation, a conclusion which may not be general. Unfortunately, any more detailed mark-up requires an enourmous amount of work and checking.
My thanks go to my colleague, Renata Blatná, who has helped with the working annotation of text and selection of pertinent passages.
Toma Erjavec
Language and Speech Group, Intelligent Systems Dept.,
Jozef Stefan Institute,
Ljubljana, Slovenia
e-mail: Tomaz.Erjavec@ijs.si
Slovene Translation: Structure Markup in TEILite
1. Introduction
The Slovene translation of Plato's 'Republic' was keyed-in by the Ljubljana 2 site (Institute for Slovene Language "Fran Ramovs", Slovene Academy for Sciences and Arts, Ljubljana, Slovenia) in the text editor Eva. This version served as the starting point for encoding the document in TEI Lite conformant markup. The task of the uptranslation was begun at the summer Nancy workshop, and finished in Ljubljana. In total, the process took about three days. The up-translation was accomplished partly via search and replace operations and macros in the editor Emacs, and partially via small Perl programs.
TEI Lite (http://www.uic.edu/orgs/tei/lite/) is a simplified version of the Text Encoding Initiative (TEI) Guidelines, which are addressed to anyone who wants to interchange information stored in an electronic form. As explained in the TEI Lite introduction, the TEI Guidelines provide a means of making explicit certain features of a text in such a way as to aid the processing of that text by computer programs running on different machines. This process of making explicit we call markup or encoding. Any textual representation on a computer uses some form of markup; the TEI came into being partly because of the enormous variety of mutually incomprehensible encoding schemes currently besetting scholarship, and partly because of the expanding range of scholarly uses now being identified for texts in electronic form. The TEI Guidelines use the Standard Generalized Markup Language (SGML) to define their encoding scheme. SGML is an international standard (ISO 8879), used increasingly throughout the information processing industries, which makes possible a formal definition of an encoding scheme, in terms of elements and attributes, and rules governing their appearance within a text. In selecting from the several hundred SGML elements defined by the full TEI scheme, a useful 'starter set' has been identified comprising the elements which almost every user should know about. Experience working with TEI Lite is invaluable in understanding the full TEI and in knowing which optional parts of the full TEI are necessary for work with particular types of text.
The simplicity, availability and extendibility of TEI Lite were the principal reasons why it was chosen as the markup scheme for the Slovene Plato. In the rest of this paper we give the structure of the TEI Lite marked-up Slovene Plato and some possible directions for further work.
2. Structure of the Corpus
As regards character representation, all non-ASCII characters appearing in The Slovene Plato (the corpus) have been substituted by SGML entities; the following entities have been used:
- Č č Š š Ž ž
- á é í ó
- when hyphen was used for intra-sentential punctuation, it was substituted by —
The corpus consists, as every TEI (Lite) document, of a header and a body. The header has four major divisions which together provide a detailed documentation of:
1. the electronic document itself and the sources from which it was derived;
2. the encoding system which has been applied;
3. descriptive information categorizing the document and its subject matter;
4. its revision history.
We will not further discuss the Slovene Plato corpus header here; suffice it to say that it has 220 lines and 105 elements detailing the above four categories.
The body of the text uses further markup. In particular, the following elements are distinguished in the body of our corpus, given together with the number of times they occur:
- DIV (203)
- HEAD (203)
- P (4252)
- LG (46)
- L (113)
- Q (4549)
- XPTR (598)
The DIV elements encodes textual divisions; we made use of two levels of DIV. The top level divides the Slovene Republic into 10 books and is marked by <DIV type="part">. Each such <DIV> is followed by the header (HEAD) of the part, which contains the text "BOOK ONE" etc. In the original, certain paragraphs are preceded by a number; these numbers were taken as second level divisions, and encoded as <DIV type="section">. Each such DIV is followed by its HEAD, containing the text "1." etc.
Paragraphs are marked by P elements, while poems or fragments of poems have been marked up by the LG (line group) elements, with each line of the poem marked by L.
The speeches of the participants of the dialogues are marked by Q elements. The opening and closing quote marks have not been in these cases retained in the corpus. Furthermore, Q elements are used to denote 'mentioned' words, so Qs also appear within Qs. For the 'mentioned' cases, quote marks have been preserved. This gives us a structure as e.g. "He said: <Q>The word is <Q>'honour'</Q></Q>." However, in the dialogues a speech often spans several paragraphs. As TEI Lite does not allow Q elements to encompass P elements, such Qs have been split to be P internal.
Finally, the text makes reference to endnotes; these have been marked up as external pointers (XPTR), e.g. with endnote number 9 being marked up as <XPTR N=endnote_number>. The XPTR element has been inserted at the closest legal TEI Lite position to where the original endnote number appeared.
3. Further Work
The TEI Lite Slovene Plato has been structurally marked-up and is available from the IDS ftp server; a WWW document describing this corpus and giving samplers of the original EVA Plato, the TEI Lite version and its HTML rendering is available via http://nl.ijs.si/telri-wg5/Republic/
For translation studies, alignment to at least sentence level of the various translations is essential. For this it would be advisable for all the Plato translations to be first TEI encoded as the Slovene was, and then sentence segmented. With such a structure, it is then relatively easy to sentence align the various translations, using one of the available implementations of the the Church & Gale algorithm, as has been done e.g. in the MULTEXT-East project (http://nl.ijs.si/ME/).
Primo Jakopin, Aleksandra Bizjak
Institute for the Slovenian Language Fran Ramovs,
Scientific Research Centre of the Slovenian Academy of Sciences and Arts,
Ljubljana, Slovenia
e-mail: primoz.jakopin@uni-lj.si, aleks@zrc-sazu.si
Internet homepage: http://www.zrc-sazu.si/isjfr/telri/platon.html
Part-of-Speech Tagging in the Slovenian Translation of Plato's Republic
In the fall of 1996 the problem of part-of-speech tagging for Slovenian was addressed as a part of the preparatory work for the upcoming new lexicons. As such tagging for Slovenian has not been approached before, the most relevant reference is the work conducted in the frame of the Copernicus project MULTEXT-East. At the time of writing this contribution an up-to-date report of this project can be found on: http://nl.ijs.si/ME/Lexica/MorphSyn/mte-D11M/mte-D11M.html (Work Package WP1 -- Task 1.1, Deliverable D1.1, Version 2.2, Milestone M, Intermediate Report, 16 October 1996). The MULTEXT-East project is coordinated by CNRS from Aix-en-Provence, France, and the languages of participants are Bulgarian, Czech, Estonian, Hungarian, Romanian, and Slovenian. The tagset developed for the project is very comprehensive and encompasses all the features of the languages mentioned. However, for the purposes of any large-scale tagging effort for only one language (Slovenian) and with lots of human-machine interaction, it was assessed as inappropriate. It has been designed to be complete and universal, and it is therefore more suitable for the software use. Its main drawback from our point of view is that the tags themselves are either not readily decipherable by the linguist performing tagging or verification of automatically tagged texts, or are so long that the tagged text has to be displayed word per line.
Let us illuminate this point with two sentences. The first, Seveda se lahko motijo. `Certainly they may be wrong.', tagged according to MULTEXT-East:
Seveda Particle
se Pronoun reflexive accusative yes personal nominal
lahko Adverb general positive
motijo. Verb main indicative present third plural no
and according to the tagset used in the project:
Seveda se lahko motijo.
È Gmp A Gcp
where Gmp stands for separate verbial morpheme and Gcp for verb, third person, plural.
The second sentence below, using the proposed tagging method, fits in two lines what would otherwise be more like a full screen of data:
In s tem trdiva ravno nasprotno od tega kar pravi Simonid.
Vpr E6 ZSKse6 Gce A Sse4 E2 ZSKse2 ZVR Gce IOme1
Its English translation, cut out of the wider context: ... if so, we shall be saying the very opposite of that which we affirmed to be the meaning of Simonides. The sentence and its translation also show clearly the vast range of the problem of translation equivalents.
The novel Pomladni dan `A day in spring' by Ciril Kosmaè, a post-war Slovenian writer, known for his excellent style, has been chosen as the testing ground (179 pages, 61.532 words). In the course of performing the task the tagset has evolved and the required tagging facilities have gradually been added to EVA, the lingware-oriented editor developed by P. Jakopin.
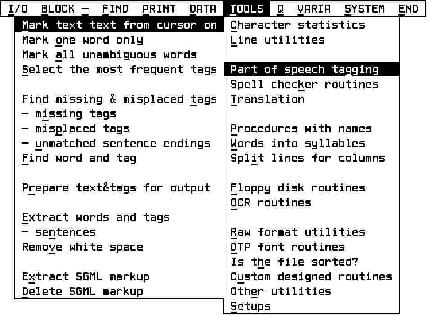
Figure 1: EVA tagger submenu with the path leading to it
The "TOOLS" main menu entry has obtained a new topic, "Part-of-speech tagging" with 15 functions; the last two are dedicated to SGML markup. The tagger makes use of four files, which reside in memory:
1. the text itself, where every second line is blank to allow the assignment of tags;
2. the dictionary of words and their tags with frequencies, which expands on the fly;
3. the explanations for unpacking of any tag into its full description
(i.e. IOme1 into name, personal, masculine, singular, case 1);
4. the history file, which is used for disambiguation.
All the files are standard EVA editor files, which makes any changes or corrections quite straightforward. The tagging is not fully automatic yet (disambiguation is still not fully operational); it could be described as computer-assisted.
So far Book 1 of Plato's Republic has been tagged and verified (9542 words out of 92730, i. e. a little over 10%). There are 574 different tags (489 in the first 9542 words of A day in spring, 1003 in all). The part-of-speech distribution for both texts shows a higher share of pronouns, conjunctions and particles with considerably less verbs in Plato's text compared to a standard Slovenian novel. In total there are 1.53% of names (added to nouns) in the Book 1 and 1.93% in A day in spring. The sample of Book 1 is probably too small for any analysis but one relation is interesting enough to deserve mention - the gender of nouns. It is 46.5% (m), 39.1% (f) and 14.4% (n) for the Plato's text and 40.3% (m), 47.1% (f) and 12.6% (n) for A day in spring. The names have contributed largely to the high frequency of masculines, without them the relation would be 41.5% (m) versus 42.7% (f). There are 145 male names in Book 1 and a single female one (Paeania), which even fails to show up in the English translation (from Paeania in Slovenian, Paeanian in English).
Part of speech Book 1 A day in spring
verbs 25.24% 32.94%
nouns 18.00 18.45
pronouns 16.50 11.47
conjunctions 12.48 8.76
prepositions 7.42 8.55
adjectives 6.78 7.02
adverbs 6.25 5.99
particles 6.96 5.71
numerals 0.31 0.64
interjections 0.05 0.44
abbreviations 0.01% 0.02%
Table 1: Part-of-speech distribution: Book 1 of Plato's Republic and A day in spring by C. Kosmaè
Alexandra Jarosová
Slovak Academy of Sciences
1/4udovit [Sinvcircumflex]túr Linguistics Institute
Bratislava, Slovakia
e-mail: sasaj@savba.savba.sk
Comparative Analysis of English and Slovak translations of Plato's Republic
Text alignment has at least two dimensions:
1) aligned corpora are treated as useful text sources of translational equivalents (with regard to an improvement of bilingual dictionaries);
2) the alignment itself can profit from some types of equivalents.
Most of the published alignment methods attempt to identify correspondences in parallel texts at the sentence level. As for word alignment, M. Kay and M. Roescheisen (1993, 121) state that it is relatively easy to establish correspondences between such words as proper names and technical terms. In the context of Plato's Republic we can ask which words in such a non-informative text have the status of "technical terms".
In this contribution I try to verify J. Sinclair's hypothesis about the key-concepts of a particular text as being "translation-protected expressions" - TPEs (TELRI WG 9 documents, 1996). Besides that I will try to expand the notion of TPE with respect to three groups of translation equivalents (TE) proposed by W. Teubert :
A. TEs found in a bilingual dictionary (BD);
B. TEs not found in BD and not regarded as appropriate;
C. TEs not found in BD but regarded as suitable.
The C list contains, as a rule, context-sensitive but recurrent TEs. W. Teubert proposes to carry out the work on these TEs by formulating rules for their generalization. The objective of W. Teubert's proposal is "to computerise the detection of those TEs which have not yet been recorded in bilingual dictionaries" (TELRI WG 9 documents, 1996). We believe that one-to-one correspondence between a specific word and its equivalent (represented predominantly in the A list) is not a basic issue of the interlingual equivalence problem. The main equivalence type is a partial equivalence which can be resolved on the word combination level. The C list contains, as a rule, a number of different multiword units associated with a source language word, or the synonyms of prototypical equivalents corresponding to source language collocations.
The result of our analysis is influenced by the fact that the two compared texts are translations of a third one and that the English translation is about 100 years older than the Slovak one. On the other hand the analysis of uneasily alignable texts can serve as a basis of detection of many different problems.
358 words (tokens) from the analysed piece of English text (2010 words) have their prototypical (i.e. found in dictionary) equivalents in the Slovak version (Dujnic,1996). Besides that there are 50 instances of correlation between proper names. Thus 407 tokens could be aligned (if lemmatized) by the existing bilingual dictionary and by an ad hoc created dictionary of proper names (e.g. Cephalus - Kefalos, Glaucon - Glaukon, Themistocles - Temistokles). This means that 20.3% of tokens in these parallel texts are alignable (approximately every sixth token). 104 instances of 357 prototypical equivalents (tokens) are grammatical words and 253 instances are autosemantic words. In spite of the high frequency of grammatical words in any text they do not represent an important group in the prototypical equivalence domain. This is caused partially by their high polyfunctionality and their position in grammatical systems of the respective languages, e.g., articles, personal and possessive pronouns, "there + to be" pattern in an English text have very low or no correspondence in a Slovak one and conversely, the Slovak reflexive particle "sa" and auxiliaries in the simple past tense have no counterparts in an English sentence. Nevertheless there are some grammatical words which demonstrate a relatively high degree of mutual bilingual correspondence. In the compared texts such words are the conjunctions: Eng. "but" (24) - Slov. "ale" (19), Eng. "if" (9) - Slov. "ak" (7), Eng. "or" (10) - Slov. "alebo" (12) and the preposition Eng. "with" (14) - Slov. "s" (12). Grammatical words are often components of fixed word combinations and these combinations (triples, quadruples etc.) can be an object of alignment (c.f. Karin Cvetko-Rasmussen's presentation at the WG9 meeting in 1996, Mannheim).
The analysis of the 253 autosemantic tokens (162 lemmas) gives us the following picture. About one half of the number are nouns (129 tokens / 78 lemmas), 83 tokens (50 lemmas) are verbs and 41 tokens (34 lemmas) are adjectives and adverbs. 63 instances (40 lemmas) of the 129 nouns have a more or less concrete meaning and 66 instances (38 lemmas) have an abstract one. 36 abstract nouns (9 lemmas) could be regarded as equivalents of translation protected expressions.
253/162 autosemantic words (tokens/lemmas)
83/50 verbs 129/78 nouns 41/34 adj./adv.
63/40 concrete 66/38 abstract
36/9 TPEs 30/29 others
Within the scope of the analysed fragment (Socrates' dialogue with Cephalus about old age) the key-concepts have been determined partially by their frequency and partially by their importance for the given topic. Some of the key concepts have not been translated by Slovak prototypical equivalents in all their occurrences but in the majority of them. From three tokens of the lemmas "life", "justice", "true" and "truth" in the English text only two tokens have prototypical equivalents in the proper Slovak sentences. (With this frequency they are included in the A list). In the group of abstract nouns regarded as key-concepts we find the following distribtion:
age (15) -- staroba (14), vek (1)
wealth (4) -- majetok (2), bohatstvo (2)
hope (3) -- nádej (3)
pleasure (3) -- pitok (1), rozkos (1), rados(1)
justice (2) -- spravodlivos (2)
true (2) -- pravdiv[yacute] (1), pravda (1)
truth (3) -- pravda (2), pravdivos (1)
life (2) -- ivot (2)
youth (2) -- mlados (2)
The key words "age", "justice", "hope", "youth", "life" are true translation protected expressions. The key words "true", "truth" and "wealth" each have 2 equivalents (the problematic case "pleasure" has 3), but these equivalents are within the scope of prototypicality. So these words could be regarded as translation protected to some degree (as a rule within 2 equivalents).
The frequent words "man" (9 occurrences) and "men" (7 occurrences) do not behave as completely translation protected expressions, but there is a specific tendency in the distribution of equivalents.
We have included (with a question mark) "man/men" in the list of concrete nouns. These nouns represent a group of words that are close to TPEs:
1 arms 3 father 1 horse 1 race
1 body 2 festival 3 man 2 relations
2 brother 2 friend 5 men 1 sacrifice
1 chair 1 garland 3 master 5 son
1 child 1 god 2 money 1 supper
1 children 2 goddess 1 night 1 threshold
1 city 2 grandfather 1 poem 1 torch
1 cloak 1 head 2 poet 1 way
1 court 1 heir 1 procession 1 word
1 evening 1 home 1 proverb 1 world
A comparison of the first three sentences in three different English translations of Plato's Republic (Jowett 1901; Waterfield 1994; Bloom 1991) has shown that these translations have very few identical words, but almost all identical words occur in places where the prototypical equivalents occur in corresponding Slovak sentences ("went", "down", "yesterday", "son", "goddess", "festival", "procession", "run", "wait", "him", "us"). Nouns are represented here by the type with concrete meaning. Another relevant observation: 11 concrete nouns occurring in Jowett's translation do not have the prototypical equivalent in the Slovak version (e.g., "inhabitant", "servant", "house", "horseman", "chair", "authors", "parents"). In Bloom's translation nine words from that group are replaced by other concrete nouns (e.g."native", "slave", "home", "stool", "poets", "fathers"), which are in prototypical equivalence relation with the corresponding Slovak words.
So the percentage of concrete nouns in the A list can be higher depending upon the degree of similarity between the two translations.
The most frequent group of verbs in the A list are, as could be expected, reporting verbs (17 say, 4 ask, answer, tell). Various forms of the lemma "to say" occur in the relevant English fragment of Republic 29 times, out of which seventeen instances were "translated" by the prototypical Slovak equivalent ("poveda"). Individual grammatical forms of this verb are not equal from the prototypical equivalence point of view. Slovak equivalents of the other reporting verbs (e.g. "to reply" and "to tell") are candidates for inclusion in the C list.
A more detailed characteristics of the C list will be the subject of my contribution to the Kaunas Seminar.
Conclusions
The A list (English words with prototypical Slovak equivalents) contains 162 autosemantic lemmas (more precisely pairs of lemmas). Almost half of them are nouns (78). Two groups of nouns (9 + 40) behave as translation protected expressions (analogues to "technical terms" in informative texts): 1. abstract nouns expressing the key-concepts of the given text (9 words) and 2. nouns naming concrete objects ("court", "garland", "poem") or persons ("servant", "brother", "poet') of the real or an imaginary world ("goddess"). In the group of verbs, reporting verbs play a similar role in this particular text.
Dictionaries and Text Sources
Dujnic, M. 1996. Moderny anglicko-slovensky slovnik. Gardenia Publishers. Bratislava
Plato. "Republic". 1994. Translated by R. Waterfield. Oxford University Press. Oxford - New York.
Plato. "Stat". 1990. In "Dialogy II." Translated by J. Spanar. Tatran Publishers. Bratislava.
"The Republic of Plato." 1901. Translated by B. Jowett. The Colonial Press. New York.
"The Republic of Plato". 1991. 2nd ed. Translated by A. Bloom. Harper Collins Publishers.
Literature
Cvetko-Rasmussen, K. 1996. TELRI internal reports and documents.
Kay, M. - Roescheisen, M. 1993. "Text-Translation Alignment." Computational Linguistics, 19 (1), 121-142.
Sinclair, J. 1996. TELRI internal reports and documents.
Teubert, W. 1966. TELRI internal reports and documents.
Ann Lawson
Corpus Research, University of Birmingham
Birmingham, Great Britain
e-mail: a.e.lawson@bham.ac.uk
Plato's Republic: Some comments on translation
All the texts of Plato's "Republic" used in the "Joint Research" project have been translated from a third language, the original Ancient Greek, thus eliminating potential mistranslations, poor or clumsy translations, omissions, explanatory additions or archaisms found in one of the versions and carried over to another. We can only talk, then, in this case of the Source Language as the Greek and Target Language as any of the myriad versions that the project has collected. As Wolfgang Teubert points out ("Comparable or Parallel Corpora?" in IJL vol 9, no 3, Sept 1996, p 239), the two Target Language versions, here English and German, each have more in common with the original source version than with each other. As I am unfamiliar with Ancient Greek, I have to treat the modern versions independently[1]. This has both disadvantages and advantages, as it makes analysis harder yet provides a more authentic framework. After all, readers of works in translation generally read translations because they lack a sufficient command of the language to read the original.
As Tognini-Bonelli points out ("Towards Translation Equivalence from a Corpus Linguistics Perspective" in IJL vol 9, no 3, Sept 1996), translation presupposes what we may call 'displaced situationality'. That is, the linguistic context (or 'co-text') is displaced because it differs in the two languages, and the situational features will differ as a different culture, situation and participants is referred to. This is still more an issue with this text because it deals with an era long past and inevitably much of the vocabulary is archaic and unfamiliar to the modern reader. The text and its language are also abstract and philosophical by nature, making the translation process yet harder as the precise meaning of concepts is more difficult to pin down and explain neatly. It is clearly also an issue whether the modern translator chooses to make the text more accessible to the reader by exchanging unfamiliar words or phrases for more modern approximations (see below).
I will use the analysis of one word and its accepted translation equivalents to investigate some aspects of translation highlighted by these parallel texts.
The word "knowledge" occurs 152 times in Jowett's translation, compared with just 95 times in the more recent Shorey translation. In the German, a search for the generally accepted translation equivalents "Wissen", "Kenntnis" and their plural and genitive forms found only 67 instances in total. Learners of German are generally taught that "Wissen" is used in the context of "knowledge about something" or "knowledge of how to do something", while "Kenntnis" is used for acquaintance with people and facts. Given these options provided by traditional paper bilingual dictionaries, the discrepancy in the frequencies seems surprising and curious.
A full statistical analysis was not possible at this stage due to restrictions in the software I was using. However, even a preliminary examination of the instances of "knowledge" which were translated differently uncovers some interesting findings.
[340e][2]
Shorey: For it when his knowledge abandons him that he who goes wrong goes wrong - when he is not a craftsman.
Jowett: they none of them err unless their skill fails them, and then they cease to be skilled artists
German: Wo sein Fachwissen auslässt, dort irrt der Irrende, worin er also nicht Fachmann ist
[350a]
Shorey: Consider then with regard to all forms of knowledge and ignorance and ignorance whether you think that anyone who knows would choose to do or say...
Jowett: And what about knowledge and ignorance in general; see whether you think that any man who has knowledge ever would wish to have the choice...
German: Was Fachwissen und Dilettantismus allgemein anlangt: Will ein Fachkundiger vor einem andern Fachkundigen etwas voraushaben...
It would appear, then, that "Fachwissen", the specialized knowledge of a subject, can be considered a suitable translation equivalent of "knowledge" in certain contexts. Since it occurs only 5 times throughout, it cannot, however, explain the numerical discrepancy.
[366d]
Shorey: (he) is aware that a man..., having won to knowledge, refrains from it.
Jowett: ...or has attained knowledge of the truth...
German: ...oder sich aus tiefer Erkenntnis} seiner ablehnt...
"Erkenntnis" would normally be translated as "recognition" or "realisation", and thus provides another translation equivalent not generally offered by conventional means.
[409c]
Shorey: ...by the instrument of mere knowledge and not by the experience of his own
Jowett: ...knowledge should be his guide, not personal experience
German: ...kraft seines Geistes, nicht der persnlichen Erfahrung
[411e]
Shorey: ...it seems that there are two arts which I would say some god gave to mankind, music and gymnastics for the service of the high-spirited principle and the love of knowledge in them
Jowett: And as there are two principles of human nature, one the spirited and the other the philosophical
German: Fr diese beiden Anlagen gab, so glaube ich, ein Gott dem Menschen die zwei Knste der Musik und der Gymnastik, fr das Mutvolle und das Geistige in ihm
"Geist" is a highly problematic word and indeed concept for English, for which there is no straightforward translation equivalent. The term can refer to the mind, the spirit or intellect, as well as a ghost, its cognate in English. It seems highly probable that as there is no such encompassing yet abstract term in English, this is a translation solution that may well not occur to a translator instinctively. The benefit of using translations originating from Greek is that the natural phraseology and word-choice is less affected by the influence of the English or German, which are rather similar languages in many ways. Any translator from German into English would have great difficulty with the adequate explanation of "Geist".
These are but some of the examples presented in more detail in Ljubljana. They indicate, however, how a network of TEs can be built up using parallel texts, which includes many which would never normally connect in traditional dictionaries. These options could be presented to the translator in context, with examples of their previous translations.
The translator must decide whether to translate "authentically", as it were, using terms similar to the ones Plato used, or whether to translate those terms into similar equivalents which the modern reader would understand. One such example is the translation of the Greek word for a voluminous cloak. In German, this is rendered as
German: Der Diener fasste mich am Mantel
Jowett: The servant took hold of me by the cloak behind
Shorey: The boy caught hold of my himation from behind
Really this last version could better be termed a non-translation, since the transliteration of the ancient Greek word is the same. It clearly referred originally to a garment unlike that familiar to a modern reader, but the translator must decide whether an approximation of meaning is more desirable than a potential misunderstanding or non-understanding. As it stands, "himation" presents an almost insuperable barrier to most modern readers, as it is unknown to all but scholars of Ancient Greece (who are unlikely to be reading in translation!) and it is found in few dictionaries.
The same aspect of choice and arbitrariness holds true for the translation of idiom. [329a]sees the quoting by a character of an old proverb, undoubtedly different in the original, but rendered as follows in the versions examined here:
German: Oft kommen wir Gleichaltrigen zusammen und besttigen das alte Sprichwort[3] .
Jowett: Men of my age flock together; we are birds of a feather, as the old proverb says
Shorey: For it often happens that some of us elders of about the same age come together and verify the old saw of like to like.
Here, it would appear that the Jowett version gives the modern reader the best concept of what the original saying expresses. There is in fact no such "saw" (another highly unfamiliar word for the modern English native speaker!) as "elders of the same age coming together". A much more natural and understandable proverb is the well-known "Birds of a feather flock together", so well known that it is often referred to only partially, as in this example, in the understanding that the reader will be able to recreate the complete proverb.
The analysis of parallel corpora underlines the creative nature of translation, as the translator adapts the text according to their understanding, ideology and their target audience. All these factors mean that any attempted translation between the German and English texts would inevitably result in a very different version of the text than those produced by the individual translations from the Ancient Greek.
For a translator, it would be useful to be able to select style, genre and era of a text. Of course, the majority of translations involve technical, legal or administrative language, and literary translations will almost certianly always be best undertaken with at the very least input from experts in the field, perhaps in conjunction with a critical edition. Even so, some translation aids to offer suggestions and examples would be useful to even the most experienced literary translator. For more technical translations, it is highly likely that options of choosing subject-area, style etc would be desirable. Much terminology alters meaning at least subtly and sometimes violently from subject-area to subject-area, and even a careful translator can easily be caught out. Further work on parallel texts can clearly assist in the development of such tools and methodologies.
[1] The Jowett Translation used is the third
edition of Jowett's multi-volume Plato, produced in 1892 and subsequently used
as the basis for most critical editions in English. The more recent English
translation was made in 1969 by Paul Shorey, Cambridge, MA, Harvard (University
Press; London, William Heinemann Ltd.). Both are available for use by TELRI
partners on the Mannheim ftp-server, as is the German text.
[2]
This number refers to the folio markings commonly found in the text, and
present in both the English and German versions.
[3] "Gleich und gleich gesellt sich gern" might
be better alternative translation.
Dan Tufis, Stefan Bruda
Romanian Academy of Sciences
Bucharest, Romania
e-mail: {tufis, bruda}@valhalla.racai.ro
Structure Markup in CES and Preliminary Statistics on Romanian Translation of Plato's "Republica"
In SGML marking-up, we used the TEI conformant CES-1 (paragraph level) encoding schema (see details on CES encoding at http://www.cs.vassar.edu/CES/), with a few sub-paragraph elements included. With a word count of 131064, the tag usage of our encoding is the following: body=1, div=32, head=32, hi=339, p=4301, q=4233, quote=39, name=700, poem=6, l=11, xptr=1341 and corr=265. The correction mark-up (corr) was used to structurally identify pieces of text which were not physically in the original but could be inferred with maximum probability. These translator's additions, marked in the printed version as well, are in most cases modifiers (adjectives, relative clauses, etc.) which if removed does not affect the grammaticality of the remaining text. The marginal notes were encoded as xptr elements with unique identifiers (the uniqueness has been achieved by appropriate concatenation of the prefix R-for Republica and the numeric and literal marginal notes: R327a, R327b,... R621.d). Comparing our CES encoding with the TEI-lite encoding of the English version (Benjamin Jowett, P. F. Collier &Son. New York, 1901 edition) a wild discrepancy has been noticed in terms of paragraph (p) and quotation (quote and q) marking: 4298 paragraphs in Romanian versus 40 in English, 4272 quotations (4233 q and 39 quote) in Romanian versus 162 (only q) in English. This was due to the very different rendering of the printed books in the two languages. By means of the on-line translator Fred (service available at the address http://www.oclc.org/fred/docs/translations/translate.html) the SGML encoding of Republica was converted into HTML (a sample can be seen at http://nl.ijs.si/telri-wg5/Republic/plato-ro.sample.html).
The text of the electronic version of "Republic" was segmented by means of a tokenizer, part of the tool-set implemented within the MULTEXT project (see the MULTEXT home-page at http://www.lpl.univ-aix.fr/projects/MULTEXT/) with the language resources we developed within the MULTEXT-EAST project (see the MULTEXT-EAST home-page at http://nl.ijs.si/ME/). The segmenter is a language independent and configurable processor used to tokenize an input text, given in one of the three possible formats: plain text (without any mark-up), a normalized SGML form (nSGML) as output by another MULTEXT tool (MTSgmlQl) and a tabular format (also specific to MULTEXT processing chain). The output of the segmenter is a tokenized form of the input text, with paragraph and sentence boundary marked-up. Punctuation, lexical items, numbers and several alpha-numeric sequences(such as dates and hours) are annotated with various tags out of a hierarchy class structured tagset. A lexical item may be an orthographic word (delimited by spaces and/or punctuation), a part of an orthographic word (clitics are split up), an abbreviation or a compound made up of two or more orthographic words. The language specific behavior of the segmenter is driven by several language resources (abbreviations, compounds, clitics, etc.). The general behavior of the segmenter (valid over several languages) can also be parametrized by means of external resources such as definition for space and punctuation, number orthography, sentence delimiters, etc.
Once the input text is tokenized, a dictionary look-up procedure, can be invoked to assign each lexical token all its possible morpho-lexical interpretations (see Figure 1, first column). This procedure was incorporated into a special XEMACS mode (mtems-mode, due to Tomaz Erjavec) in order to take advantage of the editing facilities of XEMACS. By knowing the significance of the morpho-syntactic codes we used, the mtems-mode allows a user to manually disambiguate the segmenter's output (see Figure 1, second column).
spre
|
Spsa
#
|
Spsa #
|
| a
|
I
Qn Spsa Tsfs Va--3s #
|
Qn #
|
| m
|
I
Pp1-sa--------w #
|
Pp1-sa--------w #
|
| ruga
|
Vmnp
Ncfsry Vmii3s Vmm-2s #
|
Vmnp #
|
| zeiei
|
Ncfsoy
#
|
Ncfsoy #
|
The human disambiguator is shown (at request) the significance of the MSD codes, having several editing possibilities. These codes (MSDs) are conformant with the MULTEXT-EAST linear encoding specifications (see the Morphosyntactic Encoding Description at http://nl.ijs.si/ME/Docs/Multext/multext-lexical-encoding), which themselves, represent an extension of the EAGLES proposal for morpho-syntactic annotation (see ; while EAGLES considered only Western languages, MULTEXT-EAST specifications cover two more language families: Slavic and Ugro-Finic. Romanian, being a Romance language was in principle covered by EAGLES specifications. Manual disambiguation was, as one can imagine the most time consuming phase in our processing of "Republica". It was done by a professional linguist and therefore, presumably, it is a clean and valuable language resource (among others we plan to use this disambiguated text, together with other fictional texts, for building language models and performance evaluation of tagging with several tagsets, input data for grammar induction etc.).
With respect to automatic tagging, the MSDs set is mapped, during the process of building the language model, onto a corpus tagset by means of an external resource, so by modifying only this file, we could experiment with several tagsets without modifying the disambiguated texts. A semi-automatic procedure, allows for generating from the MSD several tagsets, according to criteria specified by the designer. The Romanian MSD set has 550 codes which is definitely too much for a satisfactory performance of a HMM tagger. On the other hand, we would like to keep the corpus tags as informative as possible. This is why the first try will be carried out with a tagset containing 187 codes.
Based on the manually disambiguated texts (about. 200.000 lemmatized and MSD annotated words) we extracted some counts and frequencies. Although these statistics are not supported by enough data (we plan to extend the analysis on several million of words automatically lemmatized and disambiguated, as soon as the language models we mentioned above would ensure a reasonable precision). Here, we will only refer to the data extracted from a chunk (about 20.000 words) of text extracted from Plato's "Republica".
Figure 2 lists the most frequent 13 MSDs. This frequency list, as all the others computed based only on the selected chunk of text from "Republica", does not conform with the one based on the whole corpus, but as far as the functional words are concerned, their usage is quite accurately reflected by the partial figures discussed here. The toplist is, not surprisingly, the simple preposition subcategorizing for an accusative NP.
Spsa
|
0.080944
|
| Rgp
|
0.0753307
|
| Ccssp
|
0.0561357
|
| Ncfsrn
|
0.0326553
|
| Csssp
|
0.0326553
|
| Qs
|
0.0296372
|
| Rp
|
0.0265588
|
| Ncms-n
|
0.0265588
|
| Ncfsry
|
0.0257741
|
| Qz
|
0.0237219
|
| Vmip3s
|
0.0228164
|
| Afpms-n
|
0.0228164
|
| Vmnp
|
0.0226957
|
(first 13 most frequent)
Verb
|
0.226414
|
|
Noun
|
0.164785
|
| Pronoun
|
0.129052
|
| Adverb
|
0.120963
|
| Conjunction
|
0.0955514
|
| Preposition
|
0.0867387
|
| Particle
|
0.0613267
|
| Adjective
|
0.0514275
|
| Article
|
0.0351301
|
| Determiners
|
0.0226354
|
| Numeral
|
0.0035613
|
| Interjection
|
0.00229372
|
| Abbreviation
|
0.00012072
|
Figure 3 ranks the distribution of the wordforms according to their part-of-speech. This time, the first position is occupied by the verb (main, auxiliary, copulative), followed by nouns, pronouns, etc. We should mention that what comes under particle count is greatly due to the preposition conjunction "s'", negative adverb "nu" and preposition "a". Therefore, under a traditional classification, the adverb would come in the third position, pronoun in the fourth and so on.
s
|
Qs
|
485
|
| i
|
Ccssp
|
432
|
| nu
|
Qz
|
393
|
| de
|
Spsa
|
347
|
| c
|
Csssp
|
319
|
| mai
|
Rp
|
262
|
| fi
|
Vcip3s
|
224
|
| n
|
Spsa
|
222
|
| pe
|
Spsa
|
221
|
| avea
|
Va--3
|
156
|
| dar
|
Ccssp
|
153
|
| se
|
Px3--a--------w
|
152
|
| i
|
Rp
|
148
|
| ce
|
Pw3--r
|
144
|
| avea
|
Va--1
|
140
|
| cu
|
Spsa
|
137
|
| care
|
Pw3--r
|
131
|
581
|
Ccssp
Px3--d--------w Rp
|
| 295
|
Vcip3s
Vmip3s
|
| 222
|
Vmip1s
Vmsp1s
|
| 194
|
I
Qn Spsa Tsfs Va--3s
|
| 191
|
Csssp
Rgp
|
| 189
|
Vmnp
Vmip3s Vmm-2s
|
| 178
|
Vmip2s
Vmsp2s
|
| 154
|
Vmip3s
Pw3--r Dw3--r
|
| 154
|
Afp
Rgp
|
| 152
|
Ncms-n
Vmip1s Va--3
|
| 151
|
Va--1
Vmip1s Vmsp1s
|
| 134
|
Pw3--r
Dw3--r--e
|
| 126
|
Qf
Pp3fsa--------w Mcfsrl Tifsr Va--3s
|
| 117
|
Afpms-n
Vmp--sm
|
| 113
|
Ncfp-n
Ncfson
|
| 111
|
Vmnp
Vmii3s Vmm-2s
|
| 101
|
Afpms-n
Ncms-n Rgp Spsa
|
Other interesting data (Figure 5) were obtained by counting the ambiguity classes in a segmented (but not disambiguated text). Due to space limitation we cannot develop this issue, but these frequencies provided valuable hints concerning mapping MSDs onto corpus tags.
Editorial | Ljubljana Workshop | On the lexicons
| Interesting Events
| List of Participants
WG 9 - ORGANISING JOINT REASEARCH
Co-ordinator: John Sinclair
The Joint Research Group of TELRI has the tricky brief of learning how to work together on research, with funding only for the most basic needs. It was therefore necessary to devise projects that did not carry heavy overheads nor make large demands on the time of expert researchers - but which nevertheless were serious academic explorations.
In addition it was seen as an excellent opportunity to use the rich range of languages available among TELRI partners to stress the importance of multilingualism. Now that steps have been taken (eg in the PAROLE project) to provide, language by language, substantial generic resources, the issue arises of relating these to each other.
Hence it was decided to build a multilingual "corpus" that empasised breadth of languages rather than overall size; to begin with, a single text. With this resource we could first of all try out how difficult it was to find equivalent texts in the languages from Estonian to Albanian, tackle the problems of putting all the texts into electronic form, and then survey the field to see what tools were available to exploit this resource.
Difficulties and problems there were, but by the halfway mark of the project most had been resolved. We went on to a survey of tools for alignment etc, which gave results that were not very promising. Given the diversity of the
languages, the varied types of translation and the range of conventions used for electronic conversion, there was little we could find on the market that was likely to give good results. Although we had just a single text, we tried to imagine it as much too long to be preprocessed or marked up by hand, and concentrated on techniques that were independent of both language and size.
Most alignment software relies on consistency of paragraphs and even sentences across the translation boundary. In our study, this seemed to be very optimistic, and so, in parallel with exploring conventional alignment techniques we investigated some linguistic hypotheses which did not rely on physical alignment. The first reports were presented in Ljubljana.
This is clearly Work in Progress; scholars in very diverse circumstances focusing on the same general problem, and bringing to it their own expertise, research traditions and the individuality of the languages they are working with. Later this year, at the final TELRI seminar, we hope to present a further stage in our research, showing that we have fulfilled one of the principal aims of TELRI - to build a language resources infrastructure within which researchers throughout Europe can work easily.
The Bridge project
The second project of the Joint Research Group stresses another important aspect of TELRI - working with commercial partners, and participating in product development where success is judged in the market place. For this, partners took advantage of an opportunity to build a family of translated dictionaries. A small modern dictionary - the Cobuild Students Dictionary - was made available by courtesy of the publishers, HarperCollins. This is a monolingual English Dictionary whose definitions are written in complete sentences, thus simplifying the translation process. A translation is already published, in Brazilian Portuguese, and others are in progress; members of TELRI were asked if they would like to arrange for a translation to be made and published in their own languages. This aroused considerable interest and several ventures have started. At each TELRI event another step is taken in co-ordinating the work and passing on the experience gained; in Ljubljana the English and Portuguese texts were compared.
As each new translation is added, each Bridge partner gets a bonus, because another set of multilingual dictionaries is now possible. So there is every reason to get beyond the first hurdle, of each partner doing a translation. Also there is good reason to believe that a machine-usable lexicon of considerable generality could be derived from this pool of translations, leading to another stage of exploitation, one that could hardly be contemplated before the pool was in sight.
There are all sorts of problems to be overcome in this project; as well as the considerable linguistic ones of establishing conventions in a new kind of lexicography, there are serious economic and commercial issues to be resolved; each partner meets a unique set of circumstances and tries to resolve the difficulties. The Bridge project looks set to go on for some time, and owes a great debt to TELRI for support in inaugurating it. The presence at the Ljubljana meeting of the Slovenian publisher who will work with TELRI on the Slovenian translation was evidence that the objective of involving commercial interests is gradually being met.
Prof. John M. Sinclair Tuscan Word Centre
Azienda Casanova
409 Vellano, 51010 Pescia (PT) Italia
Phone:+39 572 40 92 51; fax 40 92 53
Editorial | Ljubljana Workshop
| News form TELRI Working Groups
| Interesting Events
| List of Participants
e-mail: pajzs@nytud.hu
The Historical Dictionary of Hungarian
The project for compiling the Historical Dictionary of Hungarian originally started more than onehundred years ago. For several decades enthusiastic men of letters have been collecting the traditional dictionary slips. This collection now contains about 5 million slips, but unfortunately they are not even alphabetised correctly, so it is very difficult to use them. Therefore in 1985 the Academy of Sciences decided to start a new project in which the first task was to create a computerised corpus of the Hungarian language. At that time there was hardly any experience in collecting and using of corpora, therefore the original ideas on the size of the planned corpus and the way of collecting it seem rather old fashioned nowadays. It was hoped that a corpus of 10 million running words from 5 centuries could properly cover the vocabulary of the language. For this purpose literary historians selected the sample texts from each century, which are being keyboarded manually. Since the sample texts are usually very small excerpts (just a few pages continuously from here and there) neither optical scanning nor the use of typesetting tapes proved to be efficient enough. Keyboarding of the texts from the earlier centuries meant additional difficulties even for the human typists, so we rather concentrated on the texts from the 19-20 centuries. Although the size of the current on-line corpus is nearly twice as large as it was originally planned (17 million words on-line, another 3 million only keyboarded but not yet controlled, corrected), we had to cope with the fact that it is still hopelessly too small for the compilation of a historical dictionary. The currently available material could more or less satisfy the needs of a new corpus based dictionary, but not the planned, OED like one. To give an idea on the usability of the corpus here are the main results of the lemmatised frequency list: the number of the different lexemes was 165.442 (not taking into consideration the homographs), only 64.090 occurred at least 3 times. While we are trying to compile the draft entries we often do not find enough examples, or they do not illustrate the different possible meanings properly, not to mention the change of the meaning throughout the centuries.
Thus after 12 years we still feel that we are at the very beginning of our historical dictionary project. During this time we have developed and purchased some software tools for retrieving our corpus and analysing it. The ready made Open Text (earlier PAT) software was bought some years ago, we have made a Hungarian interface for it with which anybody can retrieve the occurrences of the running words or expressions (via telnet). The search can be limited according to the date of writing, literary forms or authors. The results can be saved and e-mailed. We will further develop this interface in two directions: one for the external users, and one for the lexicographers and other linguists in the institute.
A morphological analyser program was also written in collaboration with MorphoLogic Ltd. (presented on the first TELRI seminar). The program segments the running words into lexemes and suffixes (prefixes). After the analysis we can retrieve the lexemes with the Open Text software. The program cannot disambiguate the homographs, because it is a pure morphological analyser. Therefore we are carrying out research in this field in the framework of GRAMLEX COPERNICUS project. The research is three-directional, we compare different methods: a pure statistical tagger (HMM), a statistical-grammatical tagger which uses local rules for the decisions, and we started to write a syntactic analyser for the same purpose. The result of these will be compared and evaluated. For writing the dictionary entries we use the WriterStation program which was dedicated for SGML text editing. Once you have decided the DTD of your dictionary it is fairly easy to develop an application in this framework. However, the version we own is relatively old (it was bought for us 4 years ago), and we are not satisfied enough with it to buy a new version. We rather intend to find a good and inexpensive tool for this purpose in the near future.
We continue to enlarge our corpus both by traditional keyboarding and by obtaining electronic texts from publishers. The main obstacle of our project is the usual one: the lack of money and manpower. The staff of the project is rather small considering the task (6 researchers and 2 keyboarders), and we have no reason to hope that it can be sufficiently increased in the near future. However we are trying to do our best in the compilation of a corpus based dictionary of Hungarian.
Bibliography
Pajzs J.: Creating a Historical Dictionary of Hungarian with the Aid of Computer T. Magay - J. Zigany: BUDALEX '88 Proceedings Akademia Kiado Budapest 1990. 559-563.
Pajzs J.: Realisation assisteé par ordinateur de grands dictionnaires franais et hongrois Cahiers détudes hongroises 3/91 Centre Interuniversitaire détudes Hongroises Université Paris III. Institut Hongrois de Paris, 47-54.
Pajzs J.: The Use of a Lemmatized Corpus for Compiling the Dictionary of Hungarian In: Using Corpora Proceedings of the 7th Annual Conference of the OUP & Centre for the New OED and Text Research. University of Waterloo Centre for the New OED, 1991. 129-136.
Pajzs J.: Project Report on the Historical Dictionary of Hungarian. in: KIEFER F. - KISS G. - PAJZS J:, eds Papers on Computational Lexicography and Text Research. Proceedings of COMPLEX '94 Budapest 1994. 205-214.
Proszeky G. - Tihanyi L.: A Fast Morphological Analyser for Lemmatizing Corpora of Agglutinative Languages. Papers in Computational Lexicography. Proceedings of COMPLEX '92. Edited by F. KIEFER, G. KISS J. PAJZS Budapest 1992. p. 275-278.
Proszeky G.: HUMOR- A Morphological System for Corpus Analysis. Proceedings of the first TELRI Seminar in Tihany. Ed. Rettig, H. Budapest 1996. p. 149-158.
John van der Voort van der Kleij, Truus Kruyt
Institute for Dutch Lexicology INL,
Leiden, The Netherlands
e-mail: {john, kruyt }@rulxho.LeidenUniv.nl
Lexicon for a linguistic annotation of Dutch text.
Introduction
The Institute for Dutch Lexicology INL started automatic linguistic annotation of present-day Dutch texts in 1992. In the framework of the EC-project NERC (Calzolari et al. 1996), linguistic software was developed which automatically provided the words (tokens) of an electronic text with headword (lemma) and Part of Speech (POS) (Panhuijsen et al. 1992). The lemmatizer-tagger, called DutchTale, consists of three components: (a) a lexicon, (b) a rule component containing morphological rules and restricted context rules (trigrammodel), and (c) a statistical component. By the lexicon, none, one or more lemma's and POS's are assigned to the tokens in the text. By the rule sets and the statistical component, tokens ambiguous with respect to lemma and/or POS are disambiguated, and many tokens not found in the lexicon (including inflected forms, compounds, etc.) still get a lemma and/or POS.
Improved versions of Dutchtale have been applied to three text corpora consultable via Internet, INL 5 Million Words Corpus 1994 (Van der Voort van der Kleij et al. 1994), a INL 27 Million Words Newspaper Corpus 1995 (Kruyt et al. 1995), and INL 38 Million Words Corpus 1996. Rather than the lexicon component, the improvements concerned the other two components. However, the lexicon now is to be revised, due to a new Dutch spelling system officially prescribed since August 1996. First, the origin and composition of the present lexicon is described. Then, we will outline which procedures are needed in order to get a lexicon covering texts written in both the former and the new spelling.
Lexicon composition
In 1990, INL produced the Herziene woordenlijst Nederlandse taal (SDU, Den Haag), a corpus-based extension of the official Dutch spelling guide Woordenlijst van de Nederlandse taal (Den Haag 1954). This list includes headwords with additional linguistic information such as gender, meaning (mainly for homographs), flected forms and allowed spelling variants. As the wordlist of '54, containing ca. 68,000 entries (headwords), was not up to date, ca. 25,000 new entries have been selected on the basis of frequency and distribution in the INL corpora. Furthermore new inflected forms have been added to the existing entries.
The extended wordlist file was the reusable source for the DutchTale lexicon. However, POS information (essential for a tagger) was not available in this source. Therefore POS has been derived automatically from special formal features in the file, such as gender encodings for the nouns, specific types of inflected forms for the verbs and the adjectives. For the remaining headwords, POS was added manually. Subsequently, all headwords and inflected forms have been written individually with their POS and their canonical form into a new file. This file hence contains an entry list consisting of headwords and inflected forms. Identical forms were reduced and their information was cumulated. As a consequence, many entries were provided with several POS and/or several headwords. For some lexicon entries, the original ambiguity was pruned according to lexical preferences, in order to prevent superfluous ambiguities. For example, the type 'heeft' may either be used as an inflected form of the verb `hebben' (to have), or as the obsolete puristic noun (lift); the latter option was pruned. As verbs had only two or three inflected forms in the original wordlist (an editorial restriction), a morphological expansion of inflected forms has been carried out by means of a program which generated additional inflected forms. Some irregular verbs needed manual intervention.
Together with a collection of proper names and abbreviations/acronyms, the lexicon contains 230.000 entries.
Lexicon revision
In 1995, INL produced the new official Dutch spelling guide Woordenlijst Nederlandse taal (SDU, Den Haag), a corpus-based extension of the spelling guide of 1954, so as to implement the Dutch spelling reform of 1995 (see Kruyt & Van Sterkenburg 1995). About 56,000 new entries were added and about 14,000 obsolete entries were removed. The database files for this product provided our second reusable source.
First, the obsolete headwords and their inflected forms were removed from the DutchTale lexicon. Next, the headwords in the lexicon which were affected by the spelling reform (marked as such in the database files), had to be respelled. These headwords, together with their inflected forms, had to be added in the DutchTale lexicon in the new orthography. Before adding them, a check was performed on the lexicon to verify whether they were already present or not. About 31,000 new headwords and their inflected forms had to be added, both in the new and in the old orthography. For the latter, it was necessary to respell the new inflected forms into the old orthography, as the database files did not contain their old forms. This also applied to the automatically expanded inflected forms of new verbs. Again the addition was preceded by a check on the lexicon to verify the absence of the newly introduced entries.
Geographic names and the words in which they are incorporated, form a separate category. Their orthography was established by a special committee and printed in a separate publication. Incorporating this list into the DutchTale lexicon requires considerable efforts, as one has to work through the index of the report and to search for all possible variants of the geographic names.
With the resulting DutchTale lexicon we are able to cover the 110,000 headwords of the latest spelling guide and their frequent inflected forms, both in the old and in the new orthography. Moreover, the coverage of our lexicon has been raised by the addition of new current headwords.
Our lemmatizer-tagger DutchTale consequently is capable to handle Dutch texts published since 1954, irrespective of whether they are written in the latest or in the older spelling.
References
Calzolari, N., M. Baker, J.G. Kruyt (eds.)(1996), Towards a Network of European Reference Corpora, Report of the NERC Consortium Feasibility Study. Linguistica Computazionale XI. Giardini Editori e Stampatori, Pisa.
Kruyt, J.G. & P.G.J. van Sterkenburg, A New Dutch Spelling Guide. In: H. Rettig (ed.) Language Resources for Language Technology, Proceedings of the first European TELRI Seminar, 133-141.
Kruyt, J.G., S.A. Raaijmakers, P.H.J. van der Kamp & R.J. van Strien, On-line Access to Linguistically Annotated Text Corpora of Dutch via Internet. In: H. Rettig (ed.) Language Resources for Language Technology, Proceedings of the first European TELRI Seminar, 173-178.
Panhuijsen, M., J. van der Voort van der Kleij & P. Wagenaar (1992), Automatic Lemmatization Experiment - An explorative study, INL Working Papers 92.02.
Van der Voort van der Kleij, J., S. Raaijmakers, M. Panhuijsen, M. Meijering & R. van Sterkenburg (1994), Een automatisch geanalyseerd corpus hedendaags Nederlands in een flexibel retrievalsysteem. In: L.G.M. Noordman & W.A.M. de Vroomen (red.) Informatiewetenschap 1994, Wetenschappelijk bijdragen aan de derde STINFON-conferentie. Tilburg, 181-194.
Editorial | Ljubljana Workshop
| On the lexicons
| News form TELRI Working Groups
| List of Participants
Institute of Formal and Applied Linguistics,
Charles University,
Prague, Czech Republic
e-mail: hajicova@ufal.ms.mff.cuni.cz
A New Impetus For The Study Of Computerized Corpora In Prague
The most recent major event in the domain of natural language processing in the Czech Republic is the establishment of the LINGUISTIC DATA LABORATORY of the Institute of Formal and Applied Linguistics, Faculty of Mathematics and Physics, Charles University, Prague.
The preparation of a complex project called "Czech Language in the Age of Computers", which started in 1996 as a joint research project of seven university departments and institutes (of Charles University in Prague and Masaryk University in Brno; the principal investigator is the Institute of Formal and Applied Linguistics) and the aim of which is to create a solid base for a versatile computerized processing of Czech language serving both as a multifaceted source of material for empirical and theoretical linguistic research as well as a base for manysided applications in the domain of text processing and information retrieval, has brought together a strong group of linguists, computational linguists, lexicologists and computer scientists who have been tied by close working contacts for quite a long time. The complex nature of the project makes it possible to integrate into the research also the students and postgradual students both of philosophical faculties and of the computer science institutes.
However, most of the project partners are faculty members of Czech universities, who have teaching and other heavy duties, and the complex character of the task requires to develop both rule-based (symbolic) and empirical (stochastic) methods of large-scale language data processing and to pay attention both to (written) language and to speech. Thus the necessity has arisen to establish a research laboratory fully concentrated on the introduction of the new aspects into the already well-established research. A support of the Czech Ministry of Education has made it possible to found the LINGUISTIC DATA LABORATORY of the Institute of Formal and Applied Linguistics, to equip the Lab with modern computers and software tools and to put together a small team of young enthusiasts broadening the scope of interests in two respects: first, to focus attention on the combination of symbolic and statistic methods of natural language processing (in order to avoid the disadvantages of them) and on the investigation of the possibilities of the application of methods based on data-driven learning, and, second, to apply these methods not only to the analysis of written text but also to speech analysis. In principle, these strictly mathematically based methods are independent of the concrete language; this opens space for mutual international cooperation, both with regard to the use of the data and the results. However, with view of the specific features of Czech as a language typologically different from the languages to which these methods have been mostly used up to now (rich inflection, word order based on other than grammatical principles), it can be expected that the research carried out in the Lab may bring interesting results for the broader Computational Linguistics and AI communities.
Editorial | Ljubljana Workshop
| News form TELRI Working Groups | On the lexicons
| Interesting Events
| List of Participants
Sue Atkions (Great Britain):
Frame Based Lexicography
Charles J. Fillmore (USA):
Frame Semantics and the Lexicon
Barbara Grosz (USA):
Issues of Discourse Analysis
Jacob Mey (Danmark):
Pragmatic Acts
Paolo Ramat (Italy):
Linguistic Categories and Linguists' Categorizations
John R. Ross (Canada):
Poetics and the Grammar of Space
Arnim von Stechow (Germany):
The Formal Semantics of Tense, Aspect, and Mood in
Subordinate Constructions in German
Mark Steedman (USA):
The Syntactic Interface
Dean S. Wotrh (USA):
Diachronic Interaction of Related Languages: Diglossa,
bilingualism, or?
The organizers still expect confirmation from Barbara H. Partee, Janet Pierrehumbert and Helmut Schnelle.
Among the invited Czech lecturers are Frantisek Èermák, Miroslav Èervenka, Eva Hajièová, Oldøich Leska, Jarmila Panevová, Jaroslav Peregrin, Vladimír Petkeviè and Petr Sgall.
Participation:
The participation fee for VMC 11 is USD 350, which includes tuition fee, accomodation, and lunches. A limited number of grants is available for students from Central and Eastern Europe. These grants cover the tuition fee, accomodation, and lunches (not the travel expenses).
FURTHER INFORMATION
Mrs. Libuse Brdièková
Institute of Formal and Applied Linguistics
Malostranské nám. 25
118 00 Prague 1
Czech Republic
phone ++420-2-2191- 4278
fax: ++420-2-2191-4309
e-mail: {brdickov, hajicova}@ufal.ms.mff.cuni.cz
Important dates:
Application for grants: 31st of May, 1997
Notification(grants): 31st of July, 1997
Paid registration: 31st of October, 1997
Editorial | Ljubljana Workshop
| News form TELRI Working Groups | On the lexicons
| Interesting Events
ANDERSEN Poul
e-mail: m764@eurokom.ie
BECI Bahri
e-mail:beci@igjl.tirana.al
BENKO Vladimírr
e-mail: jazybenk@savba.savba.sk
NEW:
tel. +421
fax +421
BIEN Janusz S.
e-mail: jsbien@plearn.edu.pl
Èermák Frantisek
e-mail: frantisek.cermak@ff.cuni.cz
ERJAVEC Toma
e-mail: Tomaz.Erjavec@ijs.si
FISIAK Jacek
e-mail: fisiak.plpuam11.bitnet
GELLERSTAM Martin
e-mail: gellerstam@svenska.gu.se
HAJIÈOVÁ Eva
HLADKÁ Barbora
e-mail: hajicova@ufal.mff.cuni.cz
hladka@ufal.mff.cuni.cz
NEW:
tel. +420 2 21 91 4 2 57
fax +420 2 21 91 43 09
JAKOPIN Primoz
e-mail: primoz.jakopin@uni-lj.si
JARO[Sinvcircumflex]OVÁ Alexandra
e-mail: sasaj@juls.savba.sk
NEW:
tel. +421
fax +421
KRUYT Truus
e-mail: kruyt@rulxho.leidenuniv.nl
MARCINKEVIÈIENÉ Rúta
e-mail: ruta.marcinkeviciene@vdu.lt
OIM Haldur
e-mail: hoim@psych.ut.ee
PAJZS Júlia
e-mail: pajzs@nytud.hu
PASKALEVA Elena
e-mail: hellen@bgearn.bitnet
PENCHEV Iordan
e-mail: jpen@bgearn.bitnet
LAURENT Romary
e-mail: Laurent.Romary@loria.fr
LAWSON Ann
e-mail: a.e.lawson@bham.ac.uk
SINCLAIR John M.
e-mail: j.sinclair@bham.ac.uk
SPEKTORS Andrejs
e-mail: aspekt@mii.lu.lv
TEUBERT Wolfgang
VOLZ Norbert
e-mail: telri@ids-mannheim.de
TUFIS Dan
e-mail: tufis@roearn.ici.ro
ZAMPOLLI Antonio
e-mail: paula@icnucevm.cnuce.cnr.it
*You can see detailed addresses in Newsletter No. 2.